超凡国际-注册赋能场景,让平台更有趣。
2025-10-10 14:37:12 103
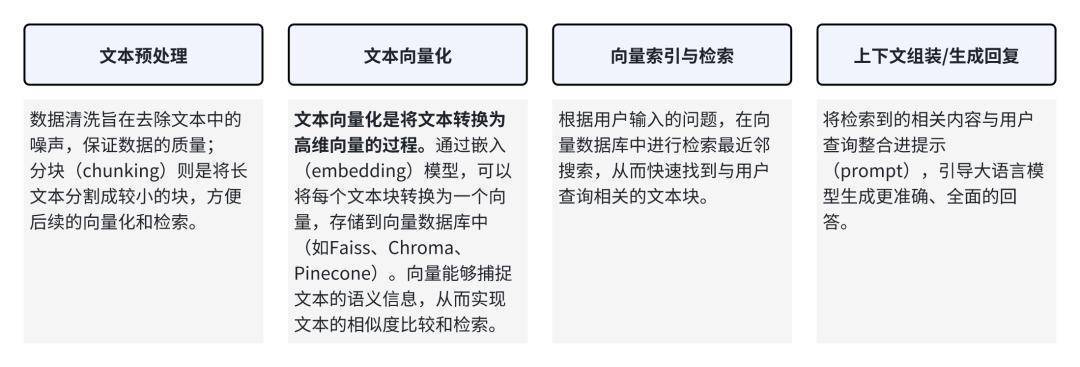
• 第一个大步骤就是将文本数据处理并进行向量化转化处理。这一步一般会用到 embedding 模型将文本块转化为向量并存储到向量数据库。
超凡国际优化提示词(prompt)设计清晰、明确的Prompt,指导LLM 更好地利用检索到的上下文信息。同时要使用Prompt 工程技巧,详情可以参考ALL About AI 系列(二):提示词工程。
优化Query1.Query 改写:对用户输入 query 进行修改或重写,通常只调整 query 结构、添加或删除关键词,或者通过近义词替换来扩展检索范围。
传统的文件知识库是用关键词匹配检索,而向量数据库是用语义匹配检索。
2.针对任务进行微调:embedding 模型的训练预料和实际检索的语料分布可能并不相同,此时在对应语料上进行 finetuning 可以显著提升检索到的内容的相关性。比如 OpenAI 也提供了代码相关的 code embedding 模型。
题图来自Unsplash,基于 CC0 协议。

本文由人人都是产品经理作者【大波子】,微信公众号:【波仔的杂货铺】豪门国际登陆,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
# ALL About AI 系列(三):RAG:检索增强生成
有些时候文档内容会比较冗余,此时可以考虑对文档进行总结,减少冗余信息。
在人工智能领域,大语言模型(LLM)虽然功能强大,但仍然存在知识更新困难和幻觉问题。为了解决这些问题,RAG(Retrieval Augmented Generation,检索增强生成)框架应运而生。
RAG的优化优化其实就是针对RAG实现流程的各个节点进行优化,其中可能有些名词过于技术,产品经理做个了解即可,主要还是对可以优化的方向有个整体认知。
优化分块(chunk)选择合适的分块大小,并使用语义分块等高级分块策略,以确保检索到的Chunk 包含完整的上下文信息。同时可以使用滑动窗口增加上下文信息。
3.Query Clarification:通常是指修正或分解用户 query 中不明确或模糊的内容,使系统更好地理解并执行相应的检索,有助于避免歧义。
• 第二个大步骤则是根据用户输入的问题,在向量数据库中进行检索临近的文本块,整合个大模型输出最后的回复。
以上就是 RAG 技术最基础的内容,随着 RAG 技术的不断发展,市面上也在有层出不穷的技术,包括多模态 RAG、graphRAG 等,当然实际使用时还是要根据具体业务选择投入产出比最优的技术路线。
RAG(Retrieval Augmented Generation,检索增强生成)是一个将大语言模型(LLM)与来自外部知识源的检索相结合的框架,以改进问答能力的工程框架。通俗来说就是给大语言模型外挂一个知识库(通常是向量数据库),使其获得自身未能掌握的数据、知识。因此RAG基本解决了LLM知识更新困难以及幻觉问题。
RAG工程相较于微调大语言模型的成本会低很多,且目前随着 RAG 工程的发展,其最终实现效果也很不错。
优化生成1.使用更强大的LLM,提高生成能力。根据具体任务,对LLM进行Finetune,提高生成效果。
优化embedding1.挑选合适的 embedding 模型:检索任务通常是判断两段内容是否相关,相似任务是判断两段内容是否相似,相关的内容不一定相似。
2.Query 纠错:通常是指尝试修正用户 query 中可能的拼写或语法错误。
2.使用合适的解码策略,如Top-ksampling、Nucleus sampling等,避免生成重复、不连贯的内容。控制生成长度,避免生成过于冗长的内容。
3.Adapter:也有研究者引入Adapter豪门国际登陆,在提取 query embedding 后进一步让 embedding 经过 Adapter,以便实现与索引更好的对齐。
豪门国际登陆
热点资讯
-
1.c7娱乐(中国游)官方网站
- 1

- c7娱乐(中国游)官方网站
- 2025-06-15
- 1
-
2.NG28(中国游)官方网站
- 2
- NG28(中国游)官方网站
- 2025-06-11
- 2
-
3.NG体育(中国游)官方网站
- 3
- NG体育(中国游)官方网站
- 2025-08-05
- 3
-
4.巅峰国际-注册赋能场景,让平台更有趣。
- 4
- 巅峰国际-注册赋能场景,让平台更有趣。
- 2025-08-25
- 4
-
5.NG28(中国游)官方网站
- 5
- NG28(中国游)官方网站
- 2025-06-09
- 5
-
6.大众娱乐-注册赋能场景,让平台更有趣。
- 6
- 大众娱乐-注册赋能场景,让平台更有趣。
- 2025-08-31
- 6
-
7.c7娱乐(中国游)官方网站
- 7
- c7娱乐(中国游)官方网站
- 2025-06-08
- 7
-
8.NG体育(中国游)官方网站
- 8
- NG体育(中国游)官方网站
- 2025-06-09
- 8
-
9.c7娱乐(中国游)官方网站
- 9
- c7娱乐(中国游)官方网站
- 2025-06-09
- 9
-
10.超凡国际-注册赋能场景,让平台更有趣。
- 10
- 超凡国际-注册赋能场景,让平台更有趣。
- 2025-11-05
- 10